Human-in-the-Loop Digital Twin for Resilient AMR Fleet Management
Building a policy-oriented, human-in-the-loop Digital Twin for incident-aware AMR fleet management, combining OPC-UA event monitoring, time-bounded surrogate optimisation, and high-fidelity simulation for governed, resilient intralogistics.
Overview
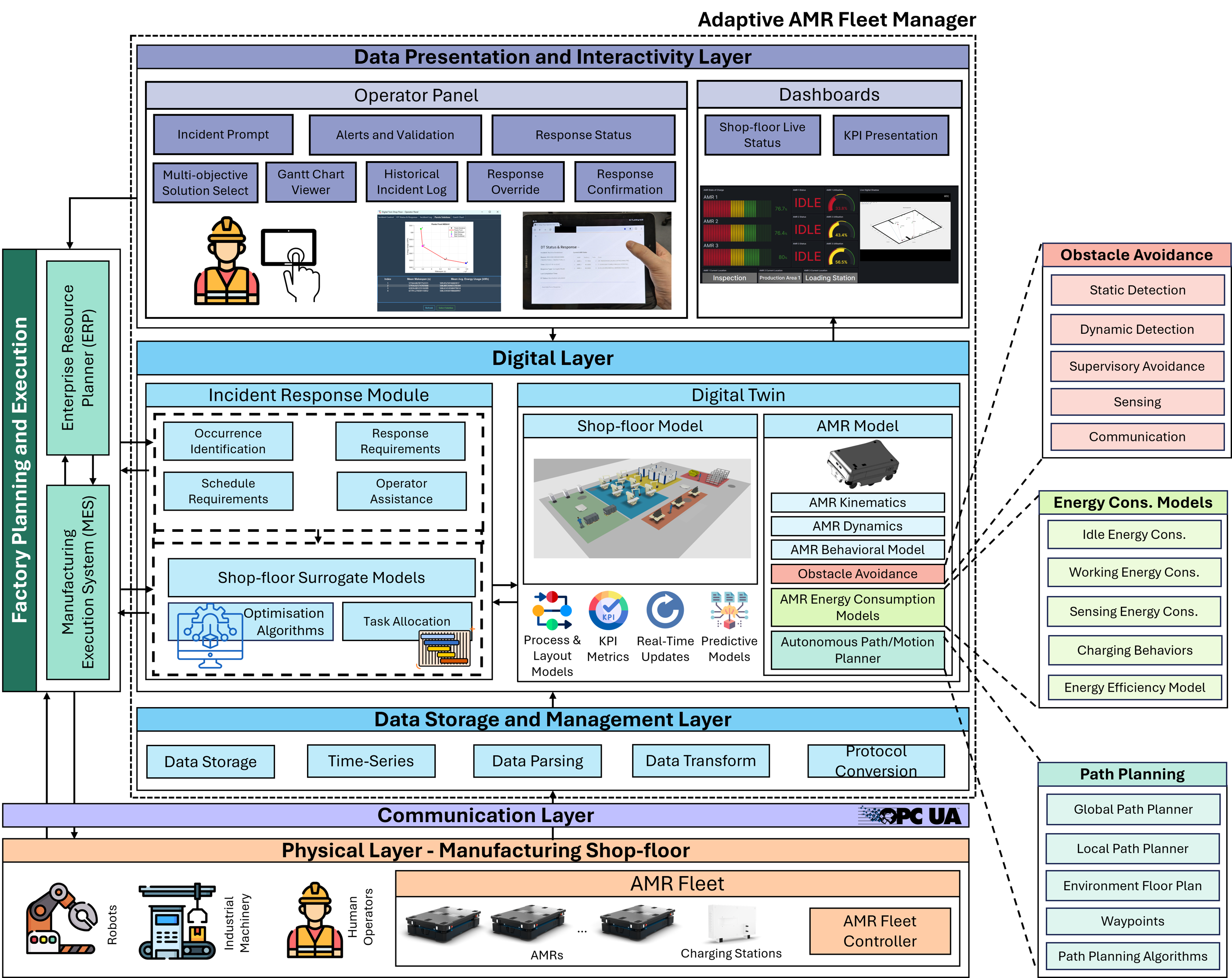
This project develops a multi-fidelity, policy-oriented Digital Twin (DT) for resilient Autonomous Mobile Robot (AMR) fleet management under disruption. The system monitors shop-floor telemetry via OPC-UA, classifies incidents (e.g., AMR breakdown, machine unavailability, demand shock), snapshots decision-relevant state, then generates incident-aware recovery schedules under a strict decision-time cap. A surrogate (low-fidelity) optimisation layer produces deployable responses within seconds, while a high-fidelity DT simulation layer provides audit, assurance, and post-decision validation. An operator-in-the-loop panel exposes Pareto trade-offs and schedule previews, enabling transparent selection, re-simulation on demand, and policy-bound overrides, with provenance captured as machine-readable decision artefacts.